Machine learning about sexual orientation?
Revised version 9/19/17.
We thank Michal Kosinski, whose work we address in this case study, for constructive feedback on the original text .
The central theme of our Calling Bullshit course is you don't always need to understand the technical details of a statistical analysis or computer algorithm to call bullshit on its use. As illustrated in the diagram below, there are typically several steps that people go through when they construct quantitative arguments. First, they assemble data that they use as inputs. Second, they feed these data into some the analytic machinery, represented below by the black box. Third, this machinery (ANOVAs, computational Bayesian analyses, deep learning algorithms, etc.) returns results of some sort. Sometimes these results are simply presented as-is, but often the results are used to justify a decision or interpretation as well.
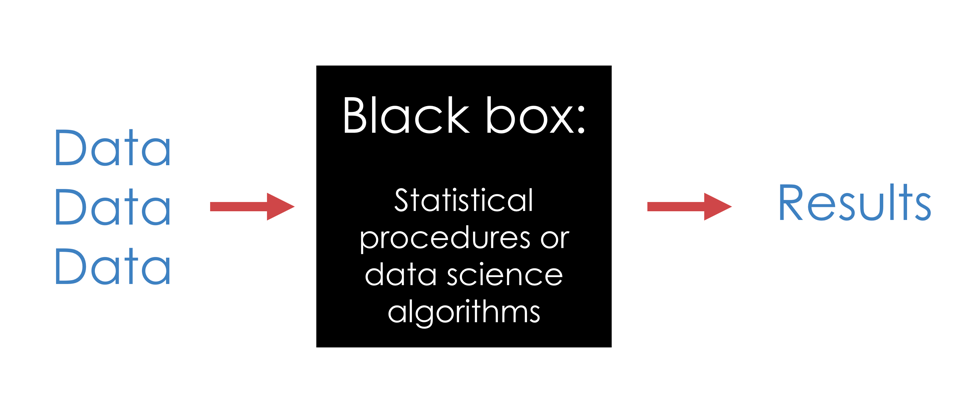
Because these statistical or algorithmic black boxes are technically complex, they tend to scare off those who might otherwise challenge an argument. Most people do not have the graduate training in statistics or machine learning that they would need to fully understand the inner workings of the black box, and so they feel that they have no right to comment on the claims being made. But black boxes should not be deterrents. We argue that one doesn't need extensive technical training in order to think critically about even highly technical analyses.
When a quantitative claim is nonsense, we can usually figure this out without having to go into the technical details of the statistics or computer algorithms. Usually the problem arises because of some kind of bias or other problem with the data that is fed in, or because of some problem with the interpretation of the results that come out. Therefore, all we need to do is to clearly and carefully examine what is going into the black box, and what comes out. This way of thinking is extremely useful, because we won't always have the expertise necessary to evaluate the details of the technical analysis itself — and even if we do, such details are not always readily available. In this particular case study, we don't need to draw upon our experience using and teaching machine learning in order to form our critique.
In a video segment from the course, we describe the black box schema in further detail. In our case study on criminal machine learning, we look at the input side: how can biases in the data that get fed into a machine learning algorithm generate misleading results? In the present case study, we look at the output side: what interpretations or conclusions are reasonable from a given set of results? We address a recent study investigating the degree to which machine processing of facial images can be used to infer sexual orientation. We concede that we are expert neither in facial recognition technology nor in the developmental endocrinology of sexual orientation. However, we do have a bit of experience trying to thinking logically about the implications of experimental results, particularly in the areas of data science and biology.
Can deep learning reveal sexual orientation?
In early September 2017, the Economist and the Guardian released a pair of oddly credulous news stories about a forthcoming paper in the Journal of Personality and Social Psychology. The paper describes a series of experiments that test whether a deep neural network can be trained to discern individuals' sexual orientations from their photographs. From an internet dating website, the authors selected photographs of nearly 8000 men and nearly 7000 women, equally distributed between heterosexual and homosexual orientations. They find that not only can their algorithm predict sexual orientation better than chance; it can outperform human judgement. (Though do note that the performance of the algorithm is far from perfect1 .)
Interpretation of the results
For obvious reasons, this paper attracted a large amount of attention from traditional and social media alike. Commentators questioned the ethical implications of conducting such a study given that stigma against homosexuality remains widespread in the US and given that homosexuality is punishable by penalties up to and including death elsewhere. While we don't find the authors' defense particularly compelling (they "merely bolted together software and data that are readily available" — maybe so, but most inhumane technologies are created this way), we do not aim to address the ethical components of the work here. We will let other more qualified scholars criticize the authors' "hermetic resistance to any contributions from the fields of sociology, cultural anthropology, feminism, or LGBT studies." We will take the authors at face value when they claim to have thought carefully about whether or not to publish the study, and we will assume they have the best of intentions. While the initial news reports did a dismal job of explaining how accurate the algorithm is, the original research paper is pretty clear and we do not intend to question the authors' methods here. In other words, we will assume that their input data are reasonable and that the black box is functioning as it should. We will assume that the technical aspects of their neural network represent reasonable choices for the problem, implemented correctly. We will set aside issues associated with a binary classification of sexual orientation. We will also take their raw results as correct. We will assume that their algorithm performs as reported, and that the study could be replicated on an independent sample of similar size.
So what is left to criticize? The authors' conclusions and interpretation of their results. First, the authors infer that the computer is picking up on features that humans are unable to detect. Second, the authors suggest that these features are the results of prenatal hormone exposure. Neither inference is warranted. We discuss these in turn.
Claim 1: The computer can detect features that humans cannot
The authors find that their deep neural network does a better job of guessing sexual orientation based on facial photographs than do humans solicited via Amazon Mechanical Turk. Based on this result, they argue that the neural net is picking up on features that humans are unable to detect. The first line of their abstract proclaims "We show that faces contain much more information about sexual orientation than can be perceived and interpreted by the human brain". The first line of the Conclusions section repeats the assertion: "The findings reported in this work show that our faces contain more information about sexual orientation than can be perceived or interpreted by the human brain."
While the results are consistent with this claim, they do not come anywhere near demonstrating it. Indeed, there is a more parsimonious explanation for why the neural net outperforms humans at this classification task: it's not a fair contest. For one thing, the authors have pitted a trained algorithm against untrained human judges. The machine had thousands of images to learn from. Humans are good at analyzing faces and may be able to generalize from the people they know — but they may have quite limited experience to draw upon and they did not get any practice at this specific task whatsoever. But that's not the biggest problem. The more important issue is that humans are notoriously bad at aggregating information to update prior probabilities, whereas computational learning algorithms can do this sort of thing very well.
To illustrate, let's look an hypothetical experiment. Imagine that we provide a machine learning algorithm with a camera feed showing a blackjack table, and instruct it to learn how to play this casino game. Blackjack is not hard (if we ignore the challenges of card counting) and a standard learning algorithm could quickly infer good rules-of-thumb for playing. Once we have trained our learning algorithm, we compare the performance of the computer to the performance of humans recruited via Amazon's Mechanical Turk2 .

Suppose we find that the computer performs substantially better than do the humans. What can we conclude? One might conjecture that the machine can see some facet of the undealt cards that people cannot. Perhaps it is picking up information from the back of the face-down card atop the dealer's deck, for example. But notice that we are asking the computer and the humans to do two separate things: (1) detect cues in the photograph of the game table, and (2) make good decisions about what to do given these cues. With their excellent visual systems and pattern detection abilities, humans are very good at the former task. (How do we prove to websites that we are humans not bots? By solving "captcha" visual processing tasks.) But it is well established that we humans are terrible at the latter task, namely making probabilistic decisions based on partial information. Thus it would be silly to conclude from this experiment that the cards are somehow marked in a way that a machine but not a human can detect. Obviously the untrained humans are simply making stupid bets.
A parallel situation arises when we ask a computer or a human to determine which of two people is more likely to be gay. As a human, we receive all sorts of information from the photographs. Rather than trying to decide whether to hit or stand given that you're holding a jack and a four while the dealer is showing a six3, we might see that one person has a baseball cap while the other wears full sideburns. One has an eyebrow piercing, the other a tattoo. Each of these facts shifts our probability estimate of the subjects' sexual orientations, but how much? And how do multiple facts interact? If the subject has a baseball cap but is clean-shaven with glasses, how does that shift our belief about the subject's orientation? Humans are terrible at these sorts of calculations, and moreover the humans in the study are untrained in these probabilities. Yet they are expected to compete against a computer algorithm which can be very good at these calculations, and which has been trained extensively.
It is no surprise whatsoever that naive humans do poorly at this task compared to a trained algorithm. There is absolutely no need to postulate secret physiognomic features below the threshold of human detection. Doing so is a profound violation of the principle of parsimony.
Claim 2: The differences the computer picks up are due to prenatal hormone exposure.
After concluding that the computer is picking up cues that go undetected by humans, Wang and Kosinski set out to explore what these cues might be. They observe that the faces of people with homosexual and heterosexual orientation have slightly different contours on average.
From this finding the authors make an inferential leap that we consider unfounded and non-parsimonious. In the abstract of their paper, Wang and Kosinski write "Consistent with the prenatal hormone theory [PHT] of sexual orientation, gay men and women tended to have gender-atypical facial morphology...." In their conclusion, "Our results provide strong support for the PHT..."
The prenatal hormone theory proposes that differences in sexual orientation arise due to differences in hormone exposure prior to birth. The authors explain:
According to the PHT, same-gender sexual orientation stems from the underexposure of male fetuses or overexposure of female fetuses to androgens that are responsible for sexual differentiation....As the same androgens are responsible for the sexual dimorphism of the face, the PHT predicts that gay people will tend to have gender-atypical facial morphology....According to the PHT, gay men should tend to have more feminine facial features than heterosexual men, while lesbians should tend to have more masculine features than heterosexual women. Thus, gay men are predicted to have smaller jaws and chins, slimmer eyebrows, longer noses, and larger foreheads; the opposite should be true for lesbians.
So do the results of the present study actually provide support for the PHT? There are two issues here. First, how strong is the evidence that facial structure differs according to sexual orientation? Second, how strong is the evidence that any differences measured in this study can be attributed to prenatal hormone exposure? We treat these in turn.
Do faces vary with sexual orientation?
First note that the present study does not constitute a rigorous experimental protocol demonstrating morphological differences under controlled conditions. The gold standard for demonstrating differences in facial shapes would be doing the morphometrics under laboratory conditions; here we are at least two steps away, using machine learning to infer average facial structures based upon self-selected photographs on a dating site. Any number of factors other than innate differences in facial structure could be involved, ranging from grooming to photo choice to lighting to the angle of the photograph (angle-correcting algorithm notwithstanding).
If this were a biology paper making within-species morphological comparisons, we would expect direct 3D measurements. Photographs lose far too much information as things are projected into the 2D plane. Biologists used to employ calipers; these days it is all about 3D scanning. While measurements from photographs appear to be more common in anthropology, things get even worse once you start looking at human faces. Humans do many things to influence the way that they present themselves and to modify their appearances. We cannot see how to reliably separate differences in physiognomy from differences in facial self-presentation based on photographs alone. 3D physical measurements strike us as essential.
For this reason, we are skeptical of previous claims about facial structure and sexual orientation. We know of none that provide direct evidence of differences based on 3D measurements. While some studies relate physiognomy with perceived sexual orientation, we are unaware of work that associates actual orientation with differences derived from 3D morphometrics. Even among the photograph-based analyses the trends appear inconsistent: the authors of the present study concede that "Previous empirical evidence provides mixed support for the gender typicality of facial features of gay men and women."
The use of dating site photos instead of three-dimensional morphometrics in the lab may not be the biggest problem with this claim. The authors argue that the faces of homosexual and heterosexual individuals have different shapes — but they never provide any sort of statistical test of specific differences.
Thus in our view, the claim that homosexual and heterosexual people have differently shaped faces remains an extraordinary claim. Extraordinary claims require extraordinary evidence. We don't get that here. Rather than providing direct evidence for this claim, the authors present us with the observation that the facial contours inferred by the deep neural net look a bit different. At the very least, the authors would need to show a statistically significant difference between face shapes. To their credit, we do get confidence limits that exclude zero on the Pearson correlation coefficient between "facial femininity" and probability of having a homosexual orientation (p.24). Moreover the algorithm can make better-than-chance guesses based upon facial outline and nose shape. The algorithm seems to be picking something up, but we worry that facial contours and "facial femininity" are readily influenced by makeup, lighting, hairstyle, angle, photo choice, and so forth. We're left with results that seem to be several steps removed from a direct statistical test for specific differences in facial features.
What about the differences in the composite faces and outlines in Figure 4 of the paper, reproduced below?

Notice that these composite faces are not constructed from all the photographs in the study or even from a random subsample of all photographs. The composite images are aggregated from the 100 faces "most and least likely to be gay." The facial contours are constructed from 500 such faces. As such, these images exaggerate differences relative to what we see in the overall sample and highlight differences that are highly diagnostic. (E.g. we might infer from the upper left composite image that even if a majority of straight men do not have a goatee, if a man does have a goatee he is highly likely to be straight.) Because these composites and contours are taken from the subsample of the population about which the algorithm is most certain, it is not clear how much can conclude from these differences in facial contours. The people whom the computer thinks are most likely to be gay (straight) may not be at all typical of the larger population of gay (straight) people.
We would find this figure more convincing if the authors had run a control of the following sort: split the full set of all photographs into two pools, at random. Train the algorithm to distinguish the pools. It presumably will not be as good at predicting random pool membership as it was predicting the homosexual/heterosexual pool membership, but it may be quite good at predicting random pool membership for the faces for which it is most certain. With enough features, some will split fairly cleanly between the two groups simply by chance, and these will be highly diagnostic. If the differences in the actual experiment are meaningful, the algorithm shouldn’t be able to make clean distinctions between the random pools even for these most-certain faces. The control composites should be highly similar and the facial landmarks for the two pools should overlap. In other words, the control composites and outlines should be nearly indistinguishable.
Do the results provide strong support for prenatal hormone exposure?
Moving on to the issue of support for the prenatal hormone exposure theory: Suppose we were convinced that this study shows real structural, physiognomic differences (as opposed to differences in self-presentation) according to sexual orientation. Does that provide strong evidence for the PHT? Well, such results would be consistent with PHT. But we don't see them as offering strong evidence. Little has been risked by doing this test. If this experiment had found no facial differences, PHT proponents might explain that away either by pointing to the same kinds of limitations in study design that we have discussed above, or by positing that the primary effects of prenatal hormone exposure are behavioral rather than physiognomic. If a test doesn't put a hypothesis on the line, results that are merely consistent with the hypothesis don't offer strong evidence in its favor.
If there are statistically significant facial differences according to sexual orientation, these could arise from any of a large number of mechanisms. A partial list, for illustration:
- Genetic differences causally associated with both facial structure and orientation.
- Genetic differences causally associated with facial structure linked to genetic differences causally associated with sexual orientation.
- Epigenetic differences causally associated with both facial structure and orientation.
- Developmental noise with correlated effects on facial structure and orientation.
- Differences in facial structure causally influencing sexual orientation due to differences in social enviroment.
- Differences in sexual orientation causally influencing differences in facial structure (this is not as silly as it may sound; for example facial width may be influenced by diet and exercise, which may be associated with sexual orientation.)
- Post-natal environmental influences causally associated with both facial structure and orientation.
We could go on, but our point is simply that we do not see why the results of the present study, even if taken at face value, should privilege PHT over other mechanistic models.
Again an imaginary experiment can provide perspective. Suppose that we were to hypothesize that born-again Christians are perfused with the light of the Holy Spirit. Humans have a hard time detecting this, we might conjecture, but machine vision may be able to discern these differences that lie below human perceptual thresholds. To test this hypothesis, we train a deep neural net to predict whether individuals are born-again Christians or not, based upon Facebook photographs. Imagine we find that not only is the neural net able to predict whether people are Christian far better than chance, but also that the algorithm picks up differences in facial illumination between born-again Christians and others.

What should we conclude from this? We might conclude that we have good evidence for the light of the Holy Spirit, but doing so would be a spectacular violation of Occam's razor on our part. All we really know is that a deep neural net can draw a distinction between these two groups for reasons that we don't really understand. The parsimonious explanation is of course that these groups present themselves differently on Facebook, whether in terms of grooming or facial expressions or photographic style or whatever else. The Holy Spirit hypothesis is clearly an extraordinary claim and we're nowhere near providing the sort of evidence that would be required to take it seriously.
Obviously the hypothesis that prenatal hormone exposure influences both facial structure and sexual orientation is somewhat less outlandish. Our point is merely that if one considers the PHT unlikely prior to reading the present study, the results do little to change one's mind. This study does not test the PHT directly, and its results are consistent with many other mechanisms. If one does consider the PHT likely before reading the present study, it offers little by way of additional evidence. While consistent with the PHT, it neither rules out a host of alternative explanations nor puts the PHT to a strong test.
Conclusions
To summarize, the Wang and Kosinski paper is consistent with the possibility that computers can detect facial features that humans cannot, and it is consistent with the hypothesis that facial differences associated with sexual orientation arise through differences in prenatal hormone exposure. These are two extremely strong claims, however, and we consider neither particularly likely a priori. Thus we diverge from the authors in our interpretation of their results. We suspect the most likely explanation for their findings is that untrained humans are poor at integrating multiple cues to make good probabilistic estimates, and that sexual orientation influences grooming and self-presentation. Both of these are well-known facts; the former can explain why the neural network outperforms humans and the latter can explain why the neural network performs substantially better than chance. To invoke mysterious features below the threshold of human perception, or effects of prenatal hormone exposure on facial structure, is to abuse the principle of parsimony.
In the author notes provided to accompany the paper and on Twitter, Wang and Kosinski have expressed the hope that their results turn out to be wrong. We are not questioning their results, but do think they are mistaken in some of their interpretations. We hope that our commentary will offer them some measure of solace.
Note regarding author's response: As is our custom, we have reached out to the authors of this piece and offered them the opportunity to respond here. We have enjoyed a productive discussion by email and look forward to posting their response here should they choose to write one.
Endnotes
1 The authors measure discriminability using the area under the ROC curve (i.e., the AUC score), which they describe not-quite-accurately as "accuracy". In the best case, for men with five photographs, AUC reaches 0.91. For women with only a single photograph, AUC drops to 0.71.
2 One might object that blackjack is a two-player game, not a decision to be made by a single individual. But this is why we chose blackjack from among all other card games. As played on the gambling floor, blackjack is a decision problem under uncertainty rather than a game in the game-theoretic sense. The player plays only against a dealer, and the dealer's moves under every possible circumstance are all prescribed in advance by the rules of the game.
3 Stand.